项目背景 :在真实的拉美电商市场中,复杂的地形、高昂的物流成本以及极度依赖分期的消费习惯,构成了独特的商业生态。本项目基于巴西头部电商平台 Olist 的真实业务数据集(涵盖 10 万+ 订单与三十多万条明细),完全通过 Python 进行底层数仓清洗与 NLP 文本降维,利用 MySQL 搭建多维业务宽表(DWD/DWS),最终产出针对供应链 SLA、运费经济学与用户体验(CX)的商业洞察体系。
🛒 数据来源 :Kaggle - Brazilian E-Commerce Public Dataset by Olist 完整源码获取 :点击访问我的 GitHub 仓库获取完整 Python 与 SQL 源码
破除原始泥潭:全维度数据资产预处理 (Python 阶段) 海外电商的真实数据往往夹杂着多语言编码冲突、业务逻辑断层以及系统底层的记录异常。为确保下游 MySQL 聚合与 Tableau 可视化的绝对精准,第一阶段必须构建严密的 Python 探查与清洗链路。
跨越语言与编码陷阱 在读取 order_reviews (用户评价表) 时,直接引发了 UTF-8 解码崩溃。通过排查,由于巴西使用葡萄牙语,部分特殊字符导致了乱码。解决策略 :精准切换编码格式,将文本表的读取引擎变更为拉美常用的 latin1,成功挽救近 10 万条宝贵的真实评价。
1 2 3 4 5 6 7 8 9 10 11 import pandas as pd import numpy as np customers=pd.read_csv('olist_customers_dataset.csv' ,encoding='utf-8' ) geolocation=pd.read_csv('olist_geolocation_dataset.csv' ,encoding='utf-8' ) order_items=pd.read_csv('olist_order_items_dataset.csv' ,encoding='utf-8' ) order_payments=pd.read_csv('olist_order_payments_dataset.csv' ,encoding='utf-8' ) order_reviews = pd.read_csv('olist_order_reviews_dataset.csv' , encoding='latin1' ) orders=pd.read_csv('olist_orders_dataset.csv' ,encoding='utf-8' ) products=pd.read_csv('olist_products_dataset.csv' ,encoding='utf-8' ) sellers=pd.read_csv('olist_sellers_dataset.csv' ,encoding='utf-8' ) category_name=pd.read_csv('product_category_name_translation.csv' ,encoding='utf-8' )
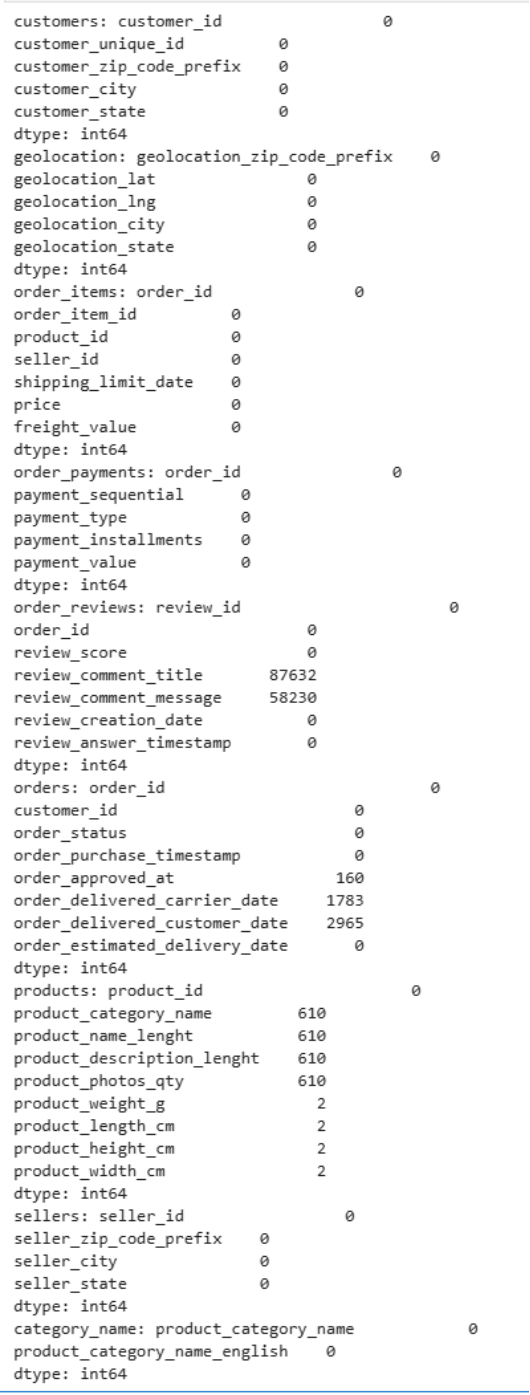
数据清洗 检查数据表里是否有缺失值: 1 2 3 4 5 6 7 8 9 10 11 12 13 dfs = { 'customers' : customers, 'geolocation' : geolocation, 'order_items' : order_items, 'order_payments' : order_payments, 'order_reviews' : order_reviews, 'orders' : orders, 'products' : products, 'sellers' : sellers, 'category_name' : category_name } for name, df in dfs.items(): print (f"{name} : {df.isnull().sum ()} " )
order_reviews (评价表):真实用户的“偷懒”行为
orders (订单事实表):漏斗流转的自然衰减 (核心亮点)
products (商品维度表):卖家上架规范的缺失1 2 3 4 5 6 7 8 9 10 11 12 13 order_reviews.fillna({ 'review_comment_title' : '' , 'review_comment_message' : '' }, inplace=True ) products['product_category_name' ] = products['product_category_name' ].fillna('unknown' ) products.fillna({ 'product_name_lenght' : 0 , 'product_description_lenght' : 0 , 'product_photos_qty' : 0 }, inplace=True ) dimensions = ['product_weight_g' , 'product_length_cm' , 'product_height_cm' , 'product_width_cm' ] for col in dimensions: products[col]=products[col].fillna(products[col].median())
检查数据表里是否有重复值: 1 2 3 4 5 6 7 8 9 10 11 12 13 dfs = { 'customers' : customers, 'geolocation' : geolocation, 'order_items' : order_items, 'order_payments' : order_payments, 'order_reviews' : order_reviews, 'orders' : orders, 'products' : products, 'sellers' : sellers, 'category_name' : category_name } for name, df in dfs.items(): print (f"{name} : {df.duplicated().sum ()} " )
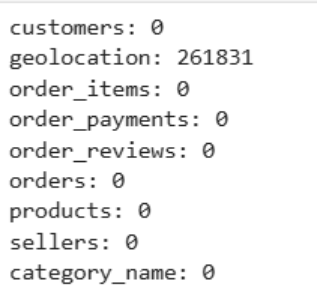
发现只有邮编表有重复值,在这张地理表里,一个邮编,绝对只对应唯一的一行数据!
1 geolocation.drop_duplicates(subset=['geolocation_zip_code_prefix' ], keep='first' , inplace=True )
检查数据表里是否有异常值: 1 2 3 4 5 6 7 8 9 10 11 12 13 dfs = { 'customers' : customers, 'geolocation' : geolocation, 'order_items' : order_items, 'order_payments' : order_payments, 'order_reviews' : order_reviews, 'orders' : orders, 'products' : products, 'sellers' : sellers, 'category_name' : category_name } for name, df in dfs.items(): print (f"{name} : {df.describe().round (2 )} " )
有以下异常点:第一,geolocation表,lat最大为42.18.lng最大为121.11而巴西维度大约在+5到-33,经度大约在-35到-74,第二,products表,weight_g商品重量最小为0,可能是虚拟物品,第三,order_payments 表,payment_installments分期数最小为0,payment_value支付金额最小也为0,可能用了全额抵扣卷/补发商品
1 2 3 condition_lat = (geolocation['geolocation_lat' ] >= -35 ) & (geolocation['geolocation_lat' ] <= 5 ) condition_lng = (geolocation['geolocation_lng' ] >= -75 ) & (geolocation['geolocation_lng' ] <= -30 ) geolocation = geolocation[condition_lat & condition_lng]
把经纬度设置好,开始检查其他的异常值
1 2 3 zero_weight_products = products[products['product_weight_g' ] == 0 ] n=len (zero_weight_products) zero_weight_products.head(n)
1 2 3 zero_payment_orders = order_payments[order_payments['payment_value' ] == 0 ] n=len (zero_payment_orders) zero_payment_orders.head(n)
1 2 3 zero_payment_orders = order_payments[order_payments['payment_installments' ] == 0 ] n=len (zero_payment_orders) zero_payment_orders.head(n)
第一张图显示,重量为 0 的商品,品类全是 cama_mesa_banho(葡萄牙语:床品卫浴)。
1 2 3 4 5 order_payments.loc[order_payments['payment_installments' ] = = 0 , 'payment_installments' ] = 1 cama_valid_data = products[(products['product_category_name' ] = = 'cama_mesa_banho' ) & (products['product_weight_g' ] > 0 )] cama_median_weight = cama_valid_data['product_weight_g' ].median() target_condition = (products['product_weight_g' ] = = 0 ) & (products['product_category_name' ] = = 'cama_mesa_banho' ) products.loc[target_condition, 'product_weight_g' ] = cama_median_weight
检查每个字段的数据类型: 1 2 3 box=[customers,geolocation,order_items,order_payments,order_reviews,orders,products,sellers,category_name] for df in box: df.info()
orders 表里的 order_purchase_timestamp(下单时间)、order_delivered_customer_date(实际送达时间),它们后面的 Dtype 全是 object
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 time_cols_orders = [ 'order_purchase_timestamp' , 'order_approved_at' , 'order_delivered_carrier_date' , 'order_delivered_customer_date' , 'order_estimated_delivery_date' ] for col in time_cols_orders: orders[col] = pd.to_datetime(orders[col]) order_reviews['review_creation_date' ] = pd.to_datetime(order_reviews['review_creation_date' ]) order_reviews['review_answer_timestamp' ] = pd.to_datetime(order_reviews['review_answer_timestamp' ]) order_items['shipping_limit_date' ] = pd.to_datetime(order_items['shipping_limit_date' ]) geolocation = geolocation.copy() customers = customers.copy() sellers = sellers.copy() customers['customer_zip_code_prefix' ] = customers['customer_zip_code_prefix' ].astype(str ).str .zfill(5 ) geolocation['geolocation_zip_code_prefix' ] = geolocation['geolocation_zip_code_prefix' ].astype(str ).str .zfill(5 ) sellers['seller_zip_code_prefix' ] = sellers['seller_zip_code_prefix' ].astype(str ).str .zfill(5 )
数据清洗完成
将清理后的数据表直接联通Navicat 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import urllib.parsefrom sqlalchemy import create_engineusername = urllib.parse.quote_plus('root' ) password = '123456' db_connection_str = f"mysql+pymysql://{username} :{password} @localhost:3306/baxi_new?charset=utf8mb4" engine = create_engine(db_connection_str) clean_dfs = { 'dwd_customers' : customers, 'dwd_geolocation' : geolocation, 'dwd_order_items' : order_items, 'dwd_order_payments' : order_payments, 'dwd_order_reviews' : order_reviews, 'dwd_orders' : orders, 'dwd_products' : products, 'dwd_sellers' : sellers, 'dim_category_translation' : category_name } print ("🚀 开始向 MySQL 数据库推送数据,请稍等..." )for table_name, df in clean_dfs.items(): print (f"正在写入表: {table_name} (共 {len (df)} 行)..." ) df.to_sql(name=table_name, con=engine, if_exists='replace' , index=False ) print ("✅ 所有数据入库大功告成!" )
构建业务分析宽表:多维指标体系提炼 (SQL 阶段) 将 Python 清洗完毕的数据通过 SQLAlchemy 批量推入 MySQL DWD(明细数据层)后,开始利用 SQL 建立面向真实业务场景的 DWS(汇总数据层)宽表。
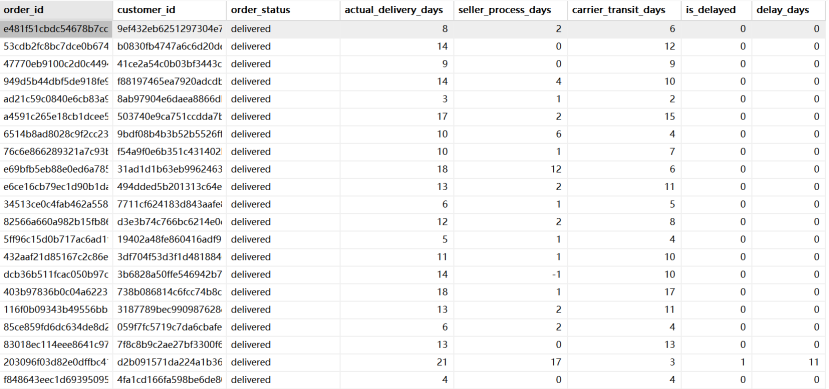
模块一:物流履约与 SLA 瓶颈归因 (Supply Chain & SLA) 业务思考:拉美电商最大的痛点在于物流。平台送货慢,到底是商家备货太拖沓,还是快递公司干线运输拉跨?必须将每个环节的耗时拆解得明明白白。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CREATE TABLE dws_logistics_sla AS SELECT order_id, customer_id, order_status, datediff(order_delivered_customer_date, order_purchase_timestamp) AS actual_delivery_days, datediff(order_delivered_carrier_date, order_approved_at) AS seller_process_days, datediff(order_delivered_customer_date, order_delivered_carrier_date) AS carrier_transit_days, CASE WHEN date (order_delivered_customer_date) > date (order_estimated_delivery_date) THEN 1 ELSE 0 END AS is_delayed, CASE WHEN date (order_delivered_customer_date) > date (order_estimated_delivery_date) THEN datediff(order_delivered_customer_date, order_estimated_delivery_date) ELSE 0 END AS delay_days FROM dwd_orders WHERE order_status = 'delivered' ;
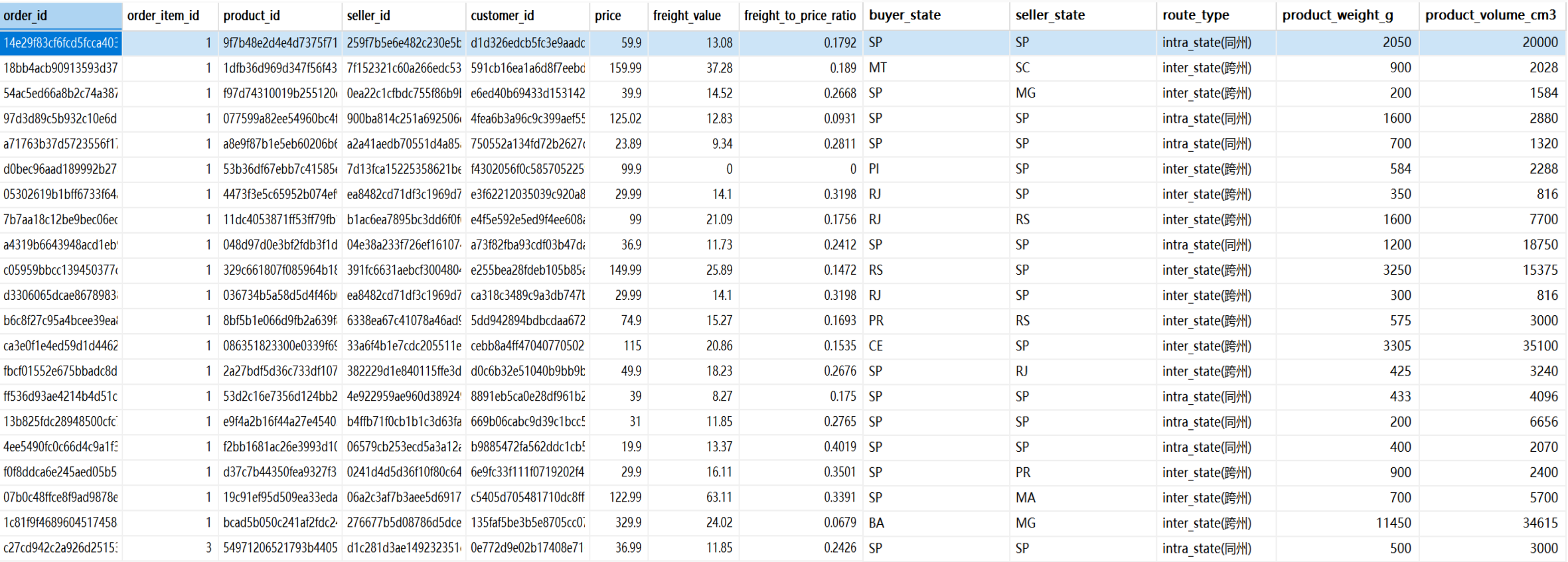
模块二:空间供需错配与运费敏感度 (Supply Chain Economics) 业务思考:巴西幅员辽阔,跨州运费是否极其高昂,甚至吃掉了用户的购买欲望和商家的利润空间?
1 2 3 4 5 6 7 8 9 10 11 12 13 select oi.order_id,oi.order_item_id,oi.product_id,oi.seller_id,c.customer_id,oi.price,oi.freight_value,round(oi.freight_value/ nullif ((oi.price+ oi.freight_value),0 ),4 ) as freight_to_price_ratio, c.customer_state as buyer_state, s.seller_state as seller_state, case when c.customer_state = s.seller_state then 'intra_state(同州)' else 'inter_state(跨州)' end as route_type,p.product_weight_g,(p.product_length_cm* p.product_width_cm* p.product_height_cm) as product_volume_cm3 from dwd_order_items as oi left join dwd_orders as o on oi.order_id = o.order_id left join dwd_products as p on oi.product_id = p.product_id left join dwd_sellers as s on oi.seller_id = s.seller_id left join dwd_customers as c on o.customer_id = c.customer_id
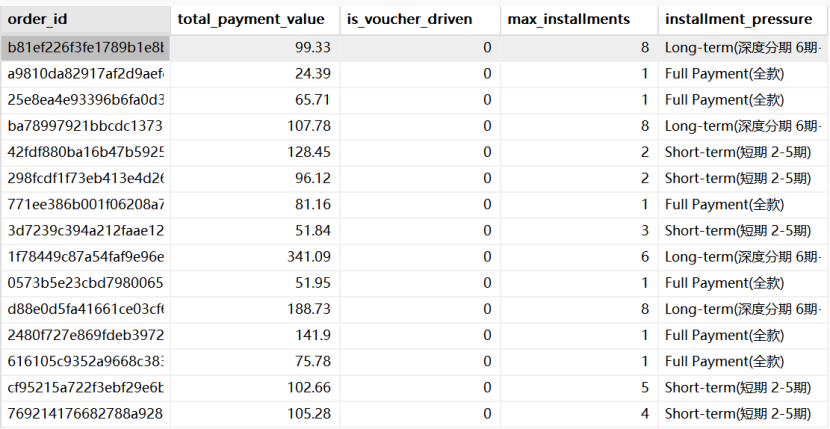
业务思考:拉美消费者极度依赖信用卡分期。用 MAX() 函数提取一个订单的最高分期数,精准刻画出用户的购买力与分期压力。
1 2 3 4 5 6 7 8 select order_id,sum (payment_value) as total_payment_value,max (case when payment_type = 'voucher' then 1 else 0 end ) as is_voucher_driven,max (payment_installments) as max_installments,case when max (payment_installments)<= 1 then 'Full Payment(全款)' when max (payment_installments) between 2 and 5 then 'Short-term(短期 2-5期)' else 'Long-term(深度分期 6期+)' end as installment_pressurefrom dwd_order_payments group by order_id ;
重磅创新:非结构化评价的 NLP 业务降维 业务思考:一个差评,如果是骂“送得太慢”,那是放错了仓库;如果是骂“一碰就碎”,那是品控崩塌。直接看平均分 3 分,根本不知道该让哪个部门出来挨打。
第 1 步:Python 自动化词典打标 将买家的“标题”和“留言”无缝拼接,通过关键字扫描完成自动化打标。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import pandas as pdfrom sqlalchemy import create_engineimport urllib.parseusername = urllib.parse.quote_plus('root' ) password = '123456' engine = create_engine(f"mysql+pymysql://{username} :{password} @localhost:3306/baxi_new?charset=utf8mb4" ) print ("🔌 正在连接数据库并读取评价数据..." )query = "SELECT order_id, review_score, review_comment_title, review_comment_message FROM dwd_order_reviews" df_reviews = pd.read_sql(query, con=engine) logistics_words = ['atraso' , 'demora' , 'lento' , 'entrega' , 'prazo' , 'não chegou' , 'n?o chegou' , 'esperando' ] quality_words = ['defeito' , 'ruim' , 'quebrado' , 'estragado' , 'falso' , 'qualidade' , 'pessimo' , 'p¨¦ssimo' ] service_words = ['atendimento' , 'vendedor' , 'suporte' , 'responder' , 'ignorou' ] def assign_business_tag (row ): score = row['review_score' ] title = str (row['review_comment_title' ]) message = str (row['review_comment_message' ]) full_text = (title + " " + message).lower() if score <= 3 : if any (word in full_text for word in logistics_words): return '物流延误' elif any (word in full_text for word in quality_words): return '商品质量差' elif any (word in full_text for word in service_words): return '客服服务差' else : return '其他体验问题' else : return '正面好评' print ("🧠 正在联合 [标题] 与 [内容] 进行全方位匹配打标..." )df_reviews['review_reason_tag' ] = df_reviews.apply(assign_business_tag, axis=1 ) print ("💾 正在将归因结果存入数据库 dws_review_tags 表..." )df_reviews.to_sql(name='dws_review_tags' , con=engine, if_exists='replace' , index=False ) print ("✅ 大功告成!全量文本 NLP 业务归因已入库!" )
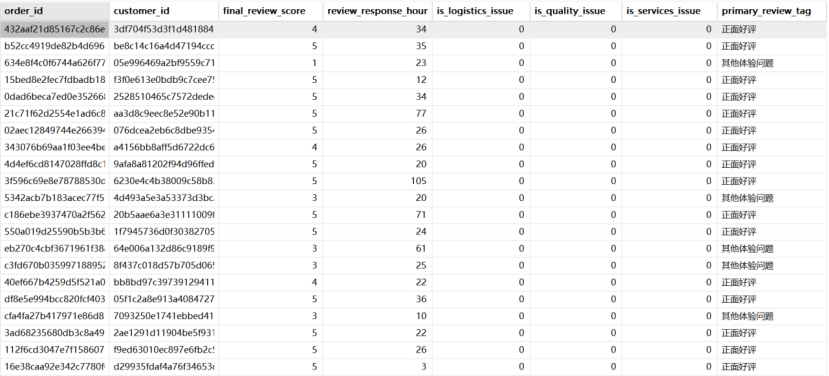
第2 步:SQL 矩阵构建与精准追责 将新生成的标签表回流至 MySQL,利用 MAX(CASE WHEN…) 构建多维缺陷矩阵。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 select o.order_id,o.customer_id,min (r.review_score) as final_review_score,timestampdiff(hour ,min (r.review_creation_date),max (r.review_answer_timestamp)) as review_response_hours, max (case when t.review_reason_tag = '物流延误' then 1 else 0 end ) as is_logistics_issue,max (case when t.review_reason_tag = '商品质量差' then 1 else 0 end ) as is_quality_issue,max (case when t.review_reason_tag = '客服服务差' then 1 else 0 end ) as is_services_issue,max (t.review_reason_tag) as primary_review_tagfrom dwd_orders as o left join dwd_order_reviews as r on o.order_id = r.order_idleft join dws_review_tags as t on o.order_id = t.order_id group by o.order_id,o.customer_id;
精准追责(CX - 客户体验): 指导商品生命周期管理(Product - 产品选品):
项目全景总结:数据驱动的“三维”闭环 数据工程层面 解决了编码问题(order_reviews 改用 latin1 读取);保留订单表中 160/1783/2965 处自然缺失(未走到该步骤);填补评论表中 8.7 万条标题和 5.8 万条内容为空字符串;对床品卫浴品类 4 个重量为 0 的商品用该类目下中位数替换;邮编字段补前导零(转为 5 位字符串);过滤掉经纬度越界的地理记录;支付金额为 0 的 9 条记录因 voucher 全额抵扣保留,但 2 条分期数为 0 的信用卡记录强制改为 1。清洗后入库 9 张表,累计约 66 万行。
SQL 建模层面 构建 dws_logistics_sla 区分商家备货与物流运输耗时,只对已送达订单计算逾期天数;构建 dws_supply_chain_economics 计算运费占比、标记同州/跨州、计算体积重;构建 dws_financial_promo 识别是否使用抵扣券、并按分期期数分为全款、短期(2-5期)、深度分期(6期+)。
NLP 归因层面 基于 9.9 万条评价,拼接标题与内容,用物流、质量、客服三组葡萄牙语关键词匹配(如 atraso、defeito、atendimento),对评分≤3的差评打标签;最终生成缺陷矩阵(is_logistics_issue、is_quality_issue、is_services_issue),将非结构化文本转化为指向具体部门的责任归属,支撑商品调仓或下架决策。