北京二手房市场深度洞察:31万次交易与13万套房源的流动性及溢价分析
项目背景:作为中国最具代表性的一线城市存量房市场,北京二手房的交易活跃度与价格分布不仅是经济基本面的晴雨表,更蕴含着深刻的城市微观空间特征。本项目基于 Kaggle 链家网开源数据集,通过 Python 进行数据清洗与 EDA,结合 SQL 进行多维度聚合提炼,最终产出宏观流动性与微观资产溢价的商业洞察报告。
🛒 数据来源:Housing price in Beijing-RUIQURM
🔗 完整源码获取:点击访问我的 GitHub 仓库获取完整 Python 与 SQL 源码
核心可视化成果 (Tableau Dashboard)
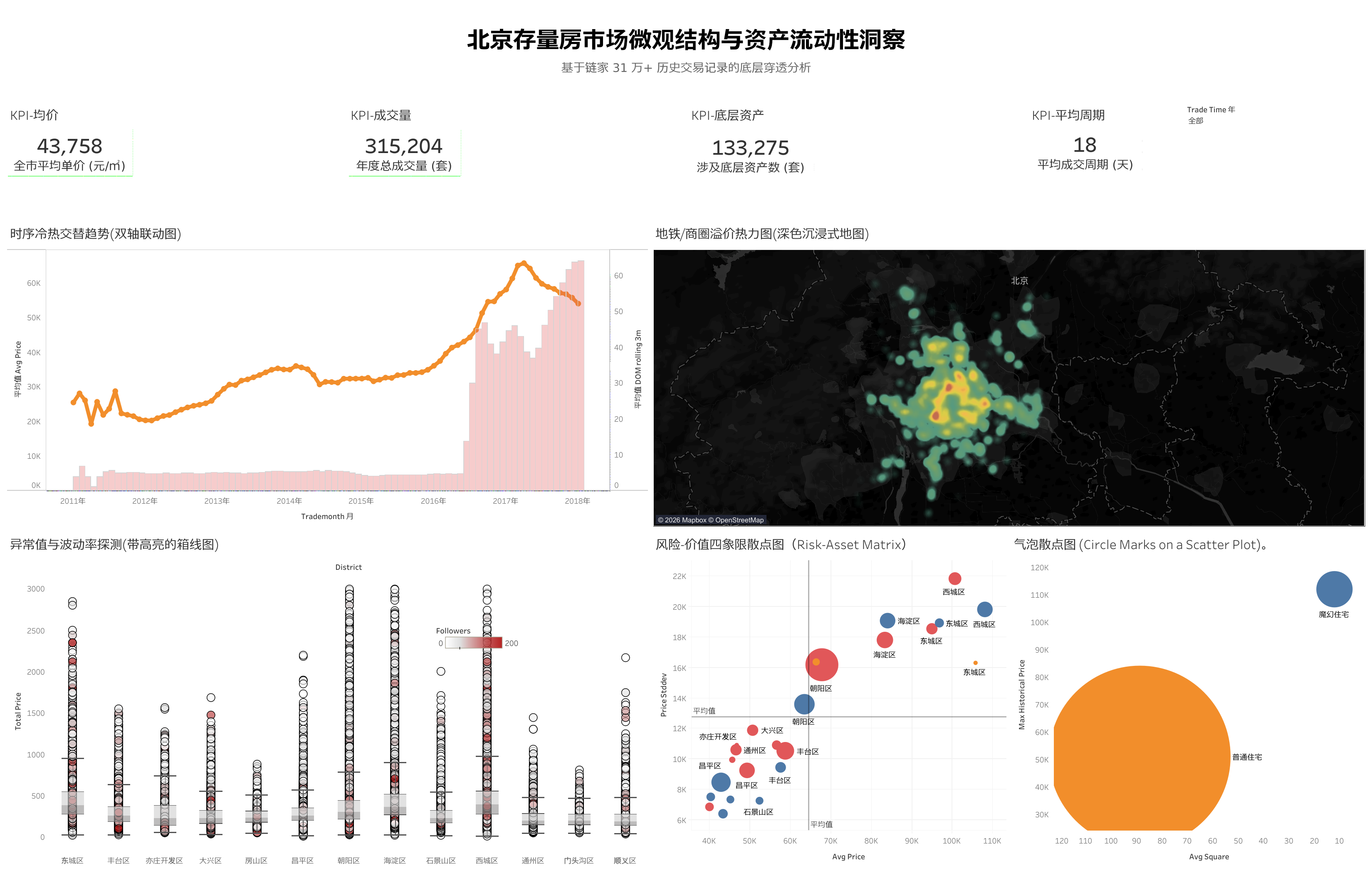
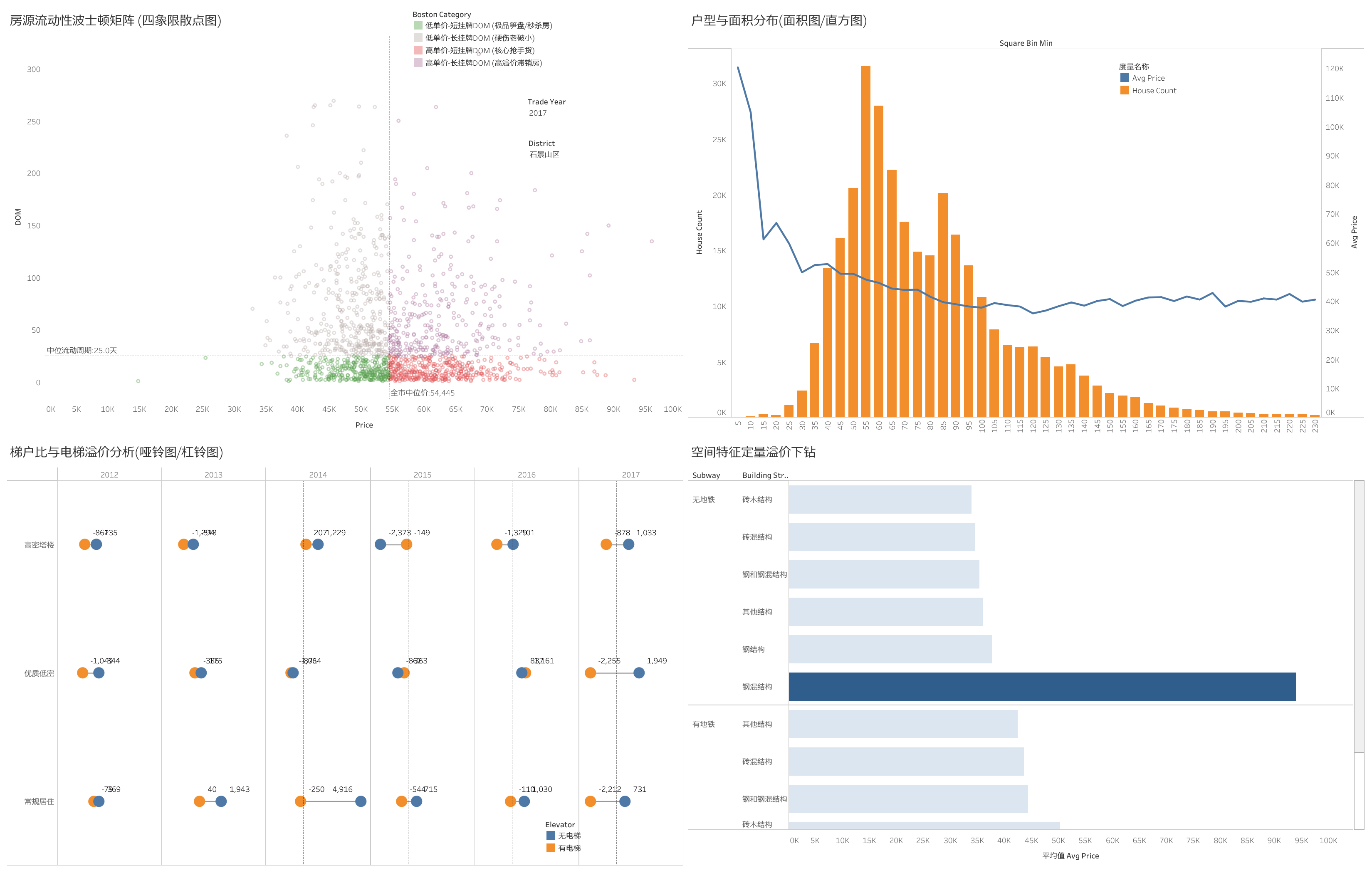
(注:由于静态图片展示受限,如果您对动态交互看板感兴趣,请点击此处查看 Tableau Public 在线版本)
数据资产预处理与特征工程 (Python 阶段)
原始数据集存在大量不规则文本、缺失值以及类型错配等数仓痛点。为保证后续 BI 看板与统计建模的绝对精准,在第一阶段构建了严密的数据清洗与特征衍生链路。
数据导入
导入数据:
1 | import pandas as pd |
编写自定义扫描算法,遍历全局数据集。通过 pd.to_numeric 的强制转换掩码(Mask)机制,精准定位并打印出潜伏在数值型字段(如 DOM、价格)中的异常中文字符与不合理小数。将“被动报错”转化为“主动排查”,彻底阻断了脏数据污染下游分析。
1 | df = pd.read_csv('new.csv', encoding='gbk', dtype=str, keep_default_na=False) |
为避免 Pandas 默认的 float64/int64 类型导致内存溢出,我设计了动态类型分配逻辑。脚本会扫描离散特征列的极限值(Min/Max),将其智能向下转型至 Int8 或 Int16。
1 | df = pd.read_csv('new.csv', encoding='gbk', dtype=str, keep_default_na=False) |
除此之外,还有两个字段没有录入成功,那就是“tradeTime”和“floor”,tradeTime直接df[‘tradeTime’] = pd.to_datetime(df[‘tradeTime’], errors=’coerce’)让其变成datetime类型,floor可能会出现未知等脏数据,所以我们用value_counts()检查一下floor这个字段排行前30的数据总量
1 | floor_counts = df['floor'].value_counts() |
发现分为五种”顶、高、中、低、底”,而且检查这个head()发现每组中间用空格,那么用正则表达式就可以简单筛选一下,把floor分成floor_type、total_floors两部分。
1 | df['tradeTime'] = pd.to_datetime(df['tradeTime'], errors='coerce') |
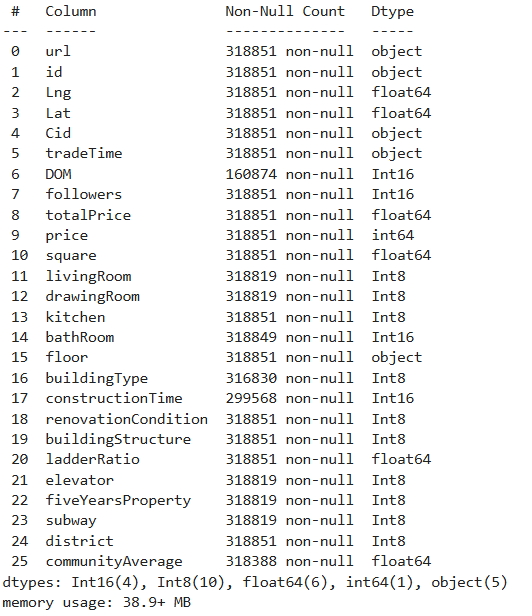
最后检查每个字段的数据类型
1 | df.info() |
数据清洗
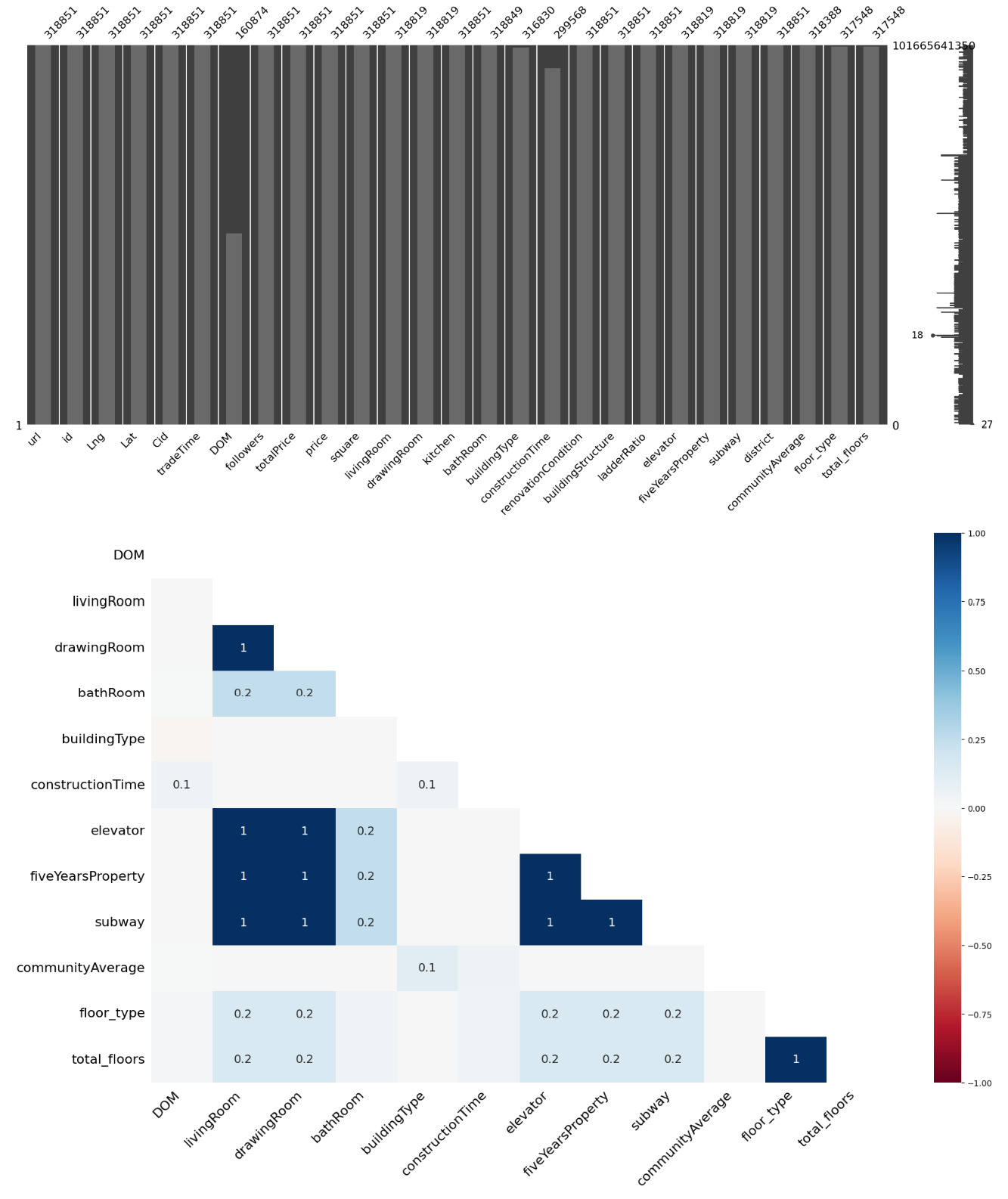
检查缺失值与他们之间关系:
1 | import missingno as msno |
检查是否有重复值:
1 | print(df.duplicated().sum()) |
发现没有重复值,检查异常值情况:
1 | df.describe().round(2).T |
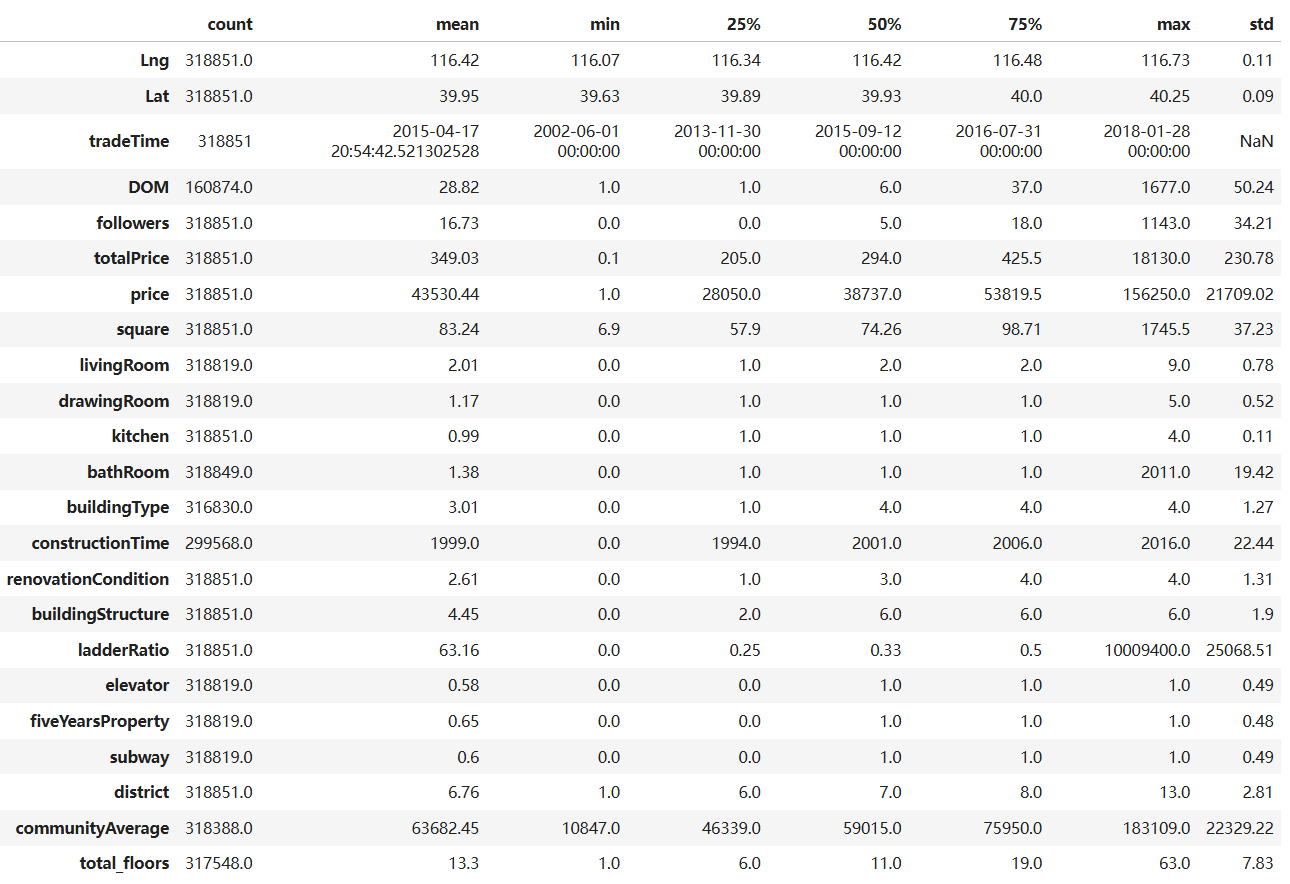
由上面检查的情况来看,此数据表,有严重的缺失值,无重复值,有异常值(total_price总价格是1000元,北京二手房有这么便宜的房子吗?price每平米价格,最小值是1元,bathRoom 最大有2011间卫生间,constructionTime建筑年代,是0年,显然不合理,ladderRatio梯户比,电梯数与每层住户数的比例,一层最多竟然高达10009400显然不合理、DOM最大有1677,这个数值也很可疑,因为75%的分位数才37。)
首先处理缺失值:
处理这个缺失值,DOM、livingRoom、drawingRoom、bathRoom、bulidingType、constructionTime、elevator、fiveYearsProperty、subway、communityAverage、total_floors、floor_type这是缺失的字段
其中,这个livingRoom、drawingRoom、bathRoom、elevator、fiveYearsProperty、subway缺失值极小,连100都不到,其中communityAverage缺少500不到,bulidingType缺少2000左右,total_floors和floor_type缺少1000不到,constructionTime缺少20000数值,DOM缺失极大
第一层:极小缺失量(不到 100 及不到 1000)—— 物理切除法(Dropna)
包含字段: livingRoom, drawingRoom, bathRoom, elevator, fiveYearsProperty, subway, total_floors, floor_type
1 | drop_cols = ['livingRoom', 'drawingRoom', 'bathRoom', 'elevator', |
第二层:衍生类属性缺失(约 500)—— 业务推导法(算术计算)
包含字段: communityAverage (小区均价)
处理方法:使用同小区 (Cid) 其他房源的单价 (price) 的均值(Mean)进行精确填补。
1 | df['communityAverage'] = df['communityAverage'].fillna( |
第三层:建筑类属性缺失(2000以上)—— 空间聚类填充法
包含字段: buildingType (建筑类型), constructionTime (建成年代),DOM(挂牌天数)
处理方法:
buildingType (代号类): 使用众数(Mode)填充。
constructionTime (年份类): 使用同小区 (Cid) 的中位数(Median)填充。如果同小区全空,退化到同行政区 (district) 填充。
DOM(年分类):使用同小区 (Cid) 的中位数(Median)填充。如果同小区全空,退化到同行政区 (district) 填充。
1 | df['buildingType'] = df['buildingType'].fillna(df['buildingType'].mode()[0]) |
注意:如果直接fillna()去嵌套这个cid_median可能会出现小数点的情况,那么需要对这个groupby分组后的数据进行round()防止再次出现‘cannot safely cast non-equivalent float64 to int8’
其次处理异常值:
total_price总价格是1000元,北京二手房有这么便宜的房子吗?price每平米价格,最小值是1元,bathRoom 最大有2011间卫生间,constructionTime建筑年代,是0年,显然不合理,ladderRatio梯户比,电梯数与每层住户数的比例,一层最多竟然高达10009400显然不合理DOM最大有1677,这个数值也很可疑,因为75%的分位数才37。
针对这个total_price和price,我们可以针对这个communityAverage和square的数值做一个简单的取值范围,小区平均价格最低为10847,面积最小值为6.9,那么这个房价总值不得低于7w元,也就是数值7
global_min_price = df[‘communityAverage’].min()
df_clean_price = df[(df[‘totalPrice’] * 10000) > (global_min_price * df[‘square’])]
然后就是这个ladderRatio,我们的思路是“用数据打败数据”,求出99%和0.1%的分位数来探明真实的业务边界,最后把不在这个区间范围的数据给删除
1 | lower_DOM = df['DOM'].quantile(0.001) |
最后检查数据是否还有问题,没问题直接导出数据
多维业务指标体系构建与数仓提炼 (SQL 阶段)
经 Python 阶段完成数据清洗与特征预建后,原始数据已具备规整的结构与可靠的字段质量。然而,面向多维度、多粒度的业务分析场景,仍需进一步完成数据向业务语义的转化。
北京楼市“冷热交替”的动态时间窗口分析
业务目标:计算二手房市场的环比(MoM)、同比(YoY)增长率,以及通过挂牌天数(DOM)的滚动平均线,找出市场从“卖方市场”向“买方市场”转换的拐点。
利用高级窗口函数(Window Functions),以月为单位,计算北京二手房市场的MoM(环比)和YoY(同比)增长率。(按照行政区划分)
1 | with new_biao as ( |
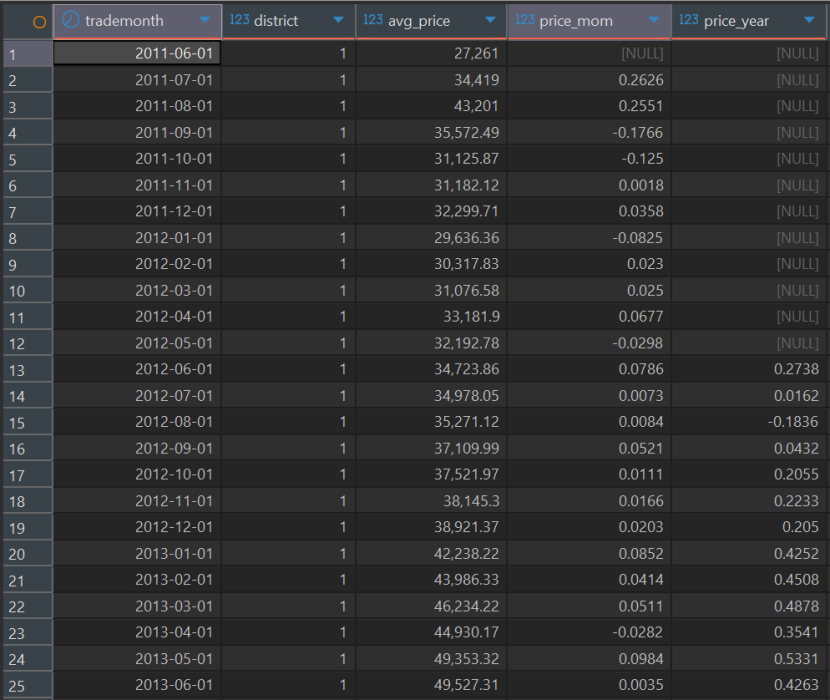
利用高级窗口函数(Window Functions),以三个月为范围,找出市场从“卖方市场”向“买方市场”转换的拐点
1 | with new_biao as ( |
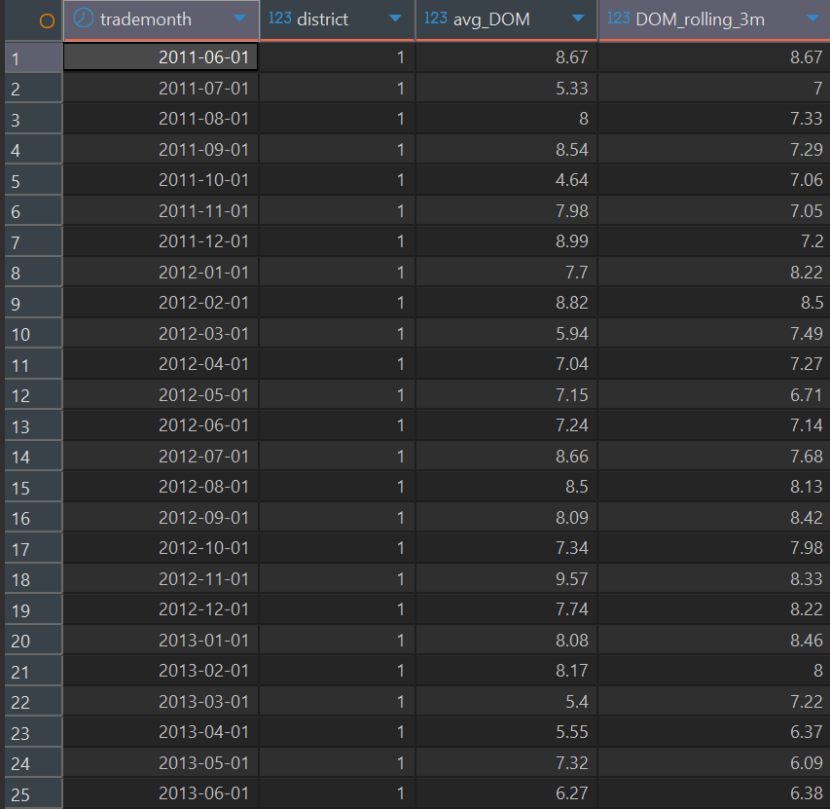
在构建这个指标时,我评估了不同窗口期的表现。如果窗口太短(如 1 个月),容易受到节假日噪音干扰;如果窗口太长(如 6 个月),指标会产生严重的滞后性,无法指导当下的业务决策。结合房产交易 1-2 个月的自然周期,我最终选择了 3 个月(单季度)作为滚动窗口,在降噪和敏锐度之间找到了最佳平衡
抗跌资产筛选(经济下行期的避险模型)
拉出历年价格数据,分析在市场整体下行或横盘的周期里,哪些行政区、哪类房源(学区 vs 远郊)的价格方差(Variance)最小,表现出最强的“抗风险能力”。(其实就是看那些地方房价最保值)
方差大:价格上蹿下跳,涨得猛跌得也惨(高风险资产)。
方差小:价格稳如老狗,不管外界怎么跌,它都不怎么掉价(抗跌避险资产)。
背景:2017年3月,北京出台了极其严格的“317新政”,楼市直接进入了长达几年的横盘/下行期。我们就拉取 2017 年之后的数据,看看哪些区域的哪种房子方差最小。
1 | select district as "行政区",buildingStructure as "建筑结构",count(*) as "成交样本量",round(avg(price),2) as "平均单价",round(varPop(price),2) as price_variance,round(stddevPop(price),2) as price_stddev |
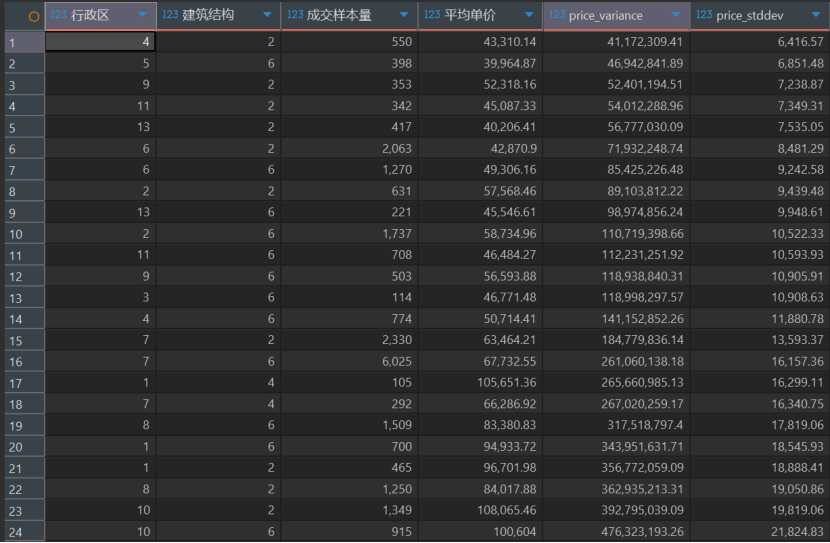
最抗跌的“刚需底盘”(看第 1 行): 【行政区 4,建筑结构 2】的房子,平均单价大概是 4.3 万/平米,它的标准差只有 6,416 元。
业务翻译: 这说明在下行周期里,这种房子的价格咬得很死,绝大部分成交价就在 43000 ± 6400 这个窄带里波动。谁也别想捡大漏,房东也不可能乱开高价。这就是典型的“保值硬通货”。
泡沫最大的“高危资产”(看第 24 行): 【行政区 10,建筑结构 6】的房子,平均单价高达 10 万/平米,但它的标准差竟然飙到了 21,824 元!
业务翻译: 这说明同样是这个区的这种房子,价格上蹿下跳极其剧烈!有的能卖 12 万,有的只能卖 8 万。这种通常是带炒作属性的“顶级学区房”或者“概念豪宅”。在下行期,这种房子的价格水分最大,是买家“屠龙刀”疯狂砍价的重灾区。
现在出现了新的问题:我知道保值了,但我怎么知道哪些房子会“溢价”?
量化‘全量溢价因子’与‘隐形折价陷阱’,实现房价波动的多源归因。
1 | WITH new_biao AS ( |
以同区同年均价为锚,逐房计算每平米绝对溢价;叠加面积、时间、区位、地铁、房龄、梯户比等全量因素,构建‘溢价归因矩阵’——正值为显性溢价(近地铁、低梯户、次新房),负值为隐性折价(高梯户、远郊、老房龄、无电梯)。
搭建“价值-流动性”波士顿矩阵
通过SQL的NTILE()甚至K-Meons思想,将房源分为四类
高单价-短挂牌DOM(核心抢手货)
高单价-长挂牌DOM(高溢价滞销房)
低单价-短挂牌DOM(极品笋盘,快速被秒)
低单价-长挂牌DOM(硬伤老破小)
这里推荐使用NTINE分桶来进行分组,原因:第一,规避“时空错位”的降维打击,如果用自定义阈值(比如 price >= 50000 THEN ‘高价’),这个模型一跑,早些年的数据和远郊区县的数据会全部掉进“低价”象限,矩阵直接瘫痪。第二,要做的是将市场切分成四个象限(高价值/高流动、低价值/低流动等)。波士顿矩阵的横纵坐标交叉点,在标准商业应用中,本来就是行业中位数或者平均值。第三,挂牌天数(DOM)虽然长尾,但排名逻辑不受影响,NTILE 靠的是排序(ORDER BY)而不是数值本身。不管是挂了 60 天还是 1000 天,在 NTILE(2) 看来,它们都排在后 50%,都会被稳稳地丢进“长挂牌 DOM”的象限里。极端的长尾数值根本无法污染排序切分的结果。
1 | with new_biao as ( |
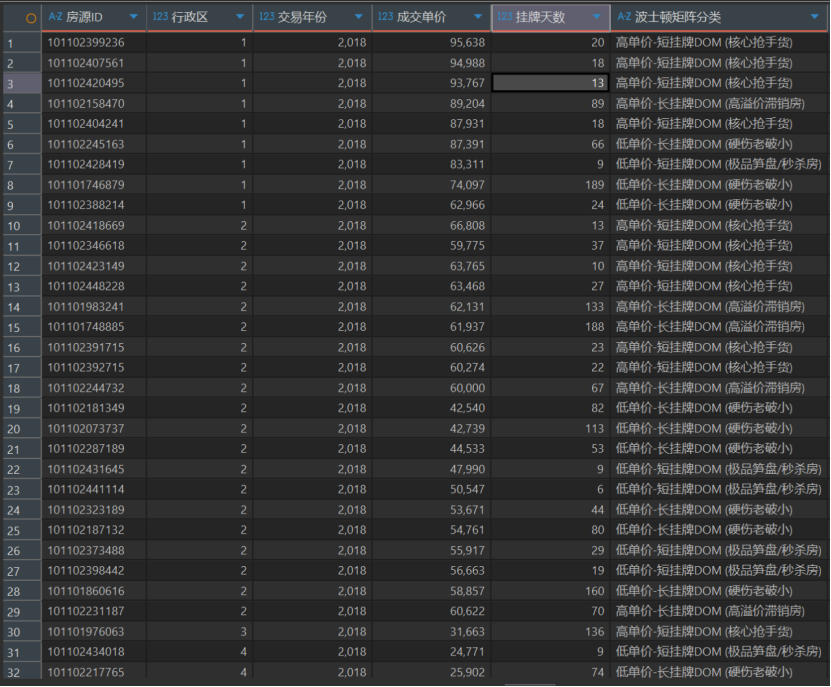
挖掘真正的“学区占坑房”特征
通过组合条件(面积〈15平米,无厨无卫,高单价),从数据海中精准提纯出这些“魔幻资产”,并分析它们的交易频次是否显著高于普通住宅。
每5平米为区间,检查各区域的价格
1 | select count(*) as `房源数量`,floor(square/5) * 5 as `面积区间_下限`,round(avg(price),2) as `平均单价` |
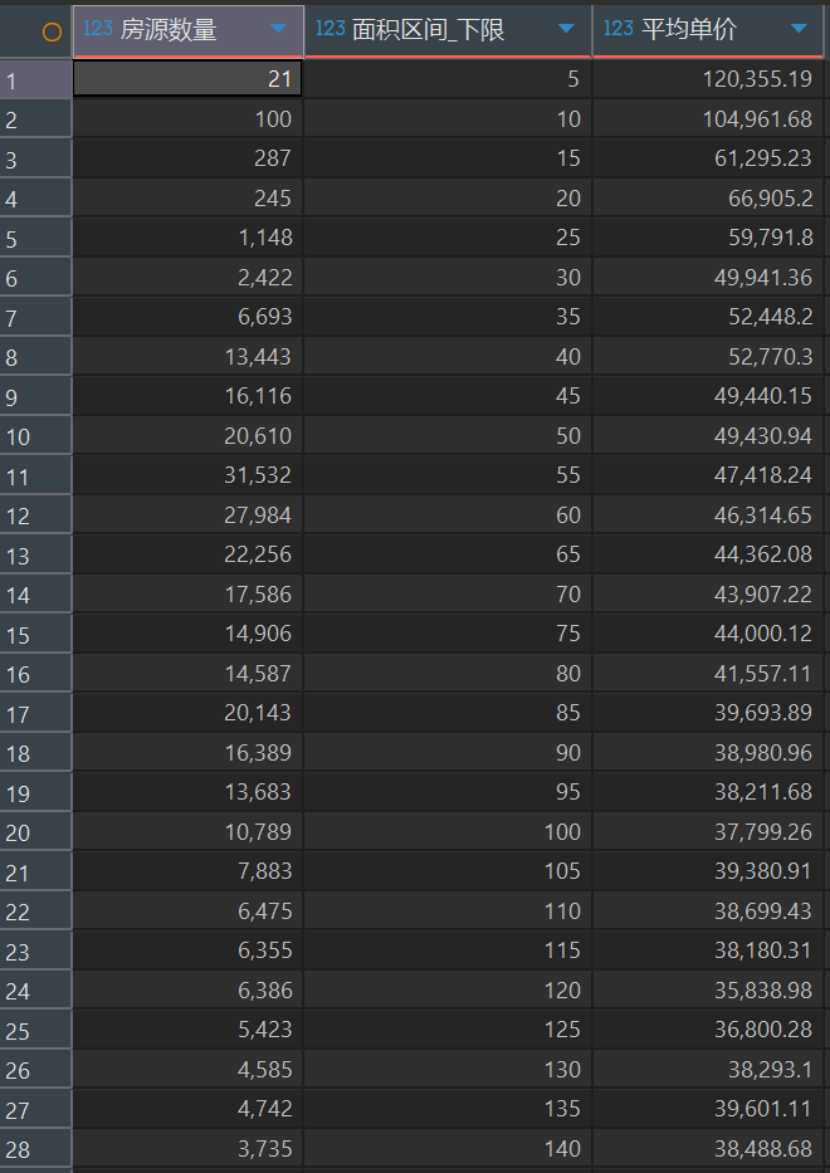
在进行极小户型(<30㎡)的探索性分析时,数据呈现出明显的价格拐点(Inflection Point)。 当面积 ≥15㎡ 时,房屋均价维持在 5-6 万元/㎡ 的合理居住区间;但当面积跌破 15㎡(进入 5-10㎡ 区间)时,均价发生断崖式突变,直接飙升至 10-12 万元/㎡。 这在统计学上构成了典型的特征突变,证明 15㎡ 以下的房产已经彻底剥离了居住价值,其超高溢价完全来自于背后的‘学区期权’。因此,本报告将 15㎡ 确立为锁定‘魔幻占坑房’的科学临界值。
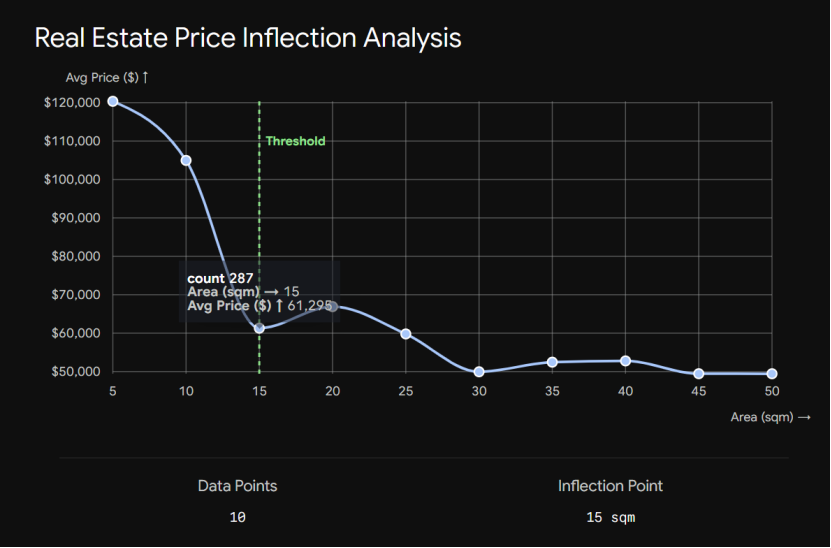
开始计算魔幻占坑房
1 | with new_biao as ( |

tableau制作可视化图表遇到的问题
在制作房源流动性波士顿矩阵的时候,发现district没有划分区域,还是数字形式,但是我们并不知道每个数字对应的行政区,所以我们可以通过查询每个数字的最大最小经纬度来判断
1 | select district,count(*),max(Lng),max(Lat),min(Lng),min(Lat) |
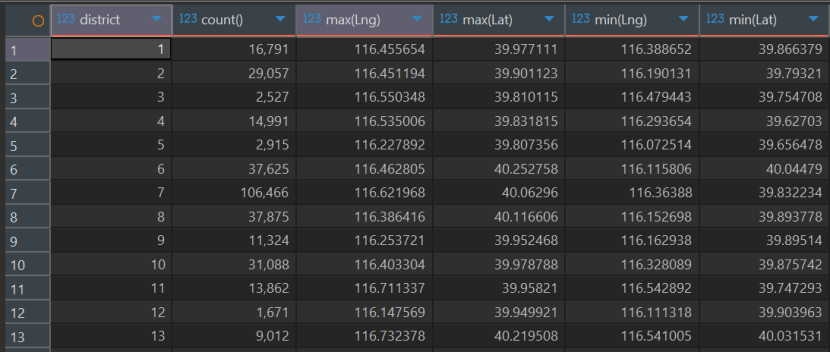
总结:1 东城区、2 丰台区、3 亦庄开发区、4 大兴区、5 房山区、6 昌平区、7 朝阳区、8 海淀区、9 石景山区、10 西城区、11 通州区、12 门头沟区、13 顺义区
项目全景总结:重塑存量资产价值的“三维”分析闭环
回顾整个北京二手房市场深度分析项目,真正的难点并非跑通一段 Python 脚本或 SQL 聚合,而是如何穿透三十万次非标准化交易的海量噪音,挖掘出隐藏在钢筋水泥背后的资产流动性与溢价规律。
本项目从始至终贯穿了以下三个核心维度的分析哲学:
维度一:全栈的数据工程与严谨的数仓思维
- 自动化异常扫描与极致降维:面对数据类型不统一及引发 cannot safely cast non-equivalent float64 to int8 的报错,编写了全字段异常扫描仪,精准定位了数值字段中掺杂的文本与带小数的脏数据 。通过引入 np.iinfo 动态评估数据边界,将核心字段智能降维至 Int8 至 Int64 类型,并采用正则 ([中高低底顶])\s*(\d+) 拆分出楼层信息,大幅优化了数据结构 。
- 分层填补与物理边界切除:针对缺失值制定了分层处理策略:对缺失不足 1000 条的极小量字段执行物理切除;对于挂牌天数(DOM)等缺失较多的特征,使用同小区(Cid)或行政区的中位数进行空间聚类填充 。通过计算小区最低均价 10847 元与最小面积 6.9 平方米,推导出 7 万元的总价理论底线,并采用 0.1% 和 99.9% 的分位数果断剔除了 DOM 高达 1677 天、梯户比达到 10009400 的极端不合理数据 。
维度二:敏锐的商业嗅觉与深度资产洞察
- 抗跌资产与高危泡沫的量化识别:锁定 2017 年“317新政”后的楼市横盘/下行期,利用方差模型精准筛选出“保值硬通货”与“高危资产” 。数据证实,【行政区 4,建筑结构 2】的房源最为抗跌,均价约 4.3 万/平米,标准差仅为 6,416 元;而带有炒作属性的【行政区 10,建筑结构 6】房源,尽管均价高达 10 万/平米,但标准差飙升至 21,824 元,揭示了极大的价格水分 。
- 时空错位修复与核心定价权解构:在量化电梯溢价时,敏锐察觉到直接对比导致的“无电梯价格更高”的逻辑悖论 。通过引入交易年份(tradeYear)窗口函数,成功剥离了 2018 年静态小区均价造成的“时空错位”干扰 。结合天安门(116.397, 39.908)为圆心的 greatCircleDistance 空间距离测算,以及梯户比分级(<=0.33 为优质低密,>0.5 为高密塔楼),彻底穿透了影响存量房定价的微观肌理 。
维度三:创新的策略建模与流动性周期解构
- 防衰减的“价值-流动性”波士顿矩阵:摒弃了极易引发“降维打击”的绝对价格阈值,创新性地采用 NTILE(2) 窗口函数,按行政区和年份进行相对排序分桶 。该模型稳健地将房源切分为“高单价-短挂牌”的核心抢手货与“低单价-长挂牌”的硬伤老破小等四大象限,彻底杜绝了长尾极端天数对业务分类的污染 。
- “魔幻占坑房”与市场拐点挖掘:通过特征组合(面积 <15 平米、无厨无卫、单价 >=1 万),从海量数据中精准提纯出超高溢价的学区房源 。数据呈现出剧烈的价格突变点:15 平米以上房屋均价维持在 5-6 万元/㎡ 的居住区间,而一旦跌破 15 平米临界值,均价则断崖式飙升至 10-12 万元/㎡ 。此外,通过反复评估降噪与敏锐度的平衡,选取 3 个月作为 DOM 滚动平均线窗口,有效排除了单一月份节假日噪音与半年期数据的滞后性,精准捕捉到了市场从卖方向买方转换的周期拐点 。
