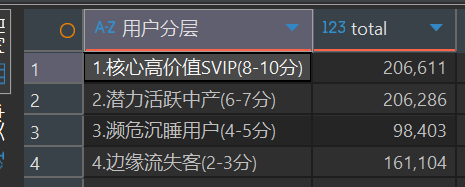
WITH new_biao AS ( SELECT user_id, dateDiff('day', max(date_id), toDate('2017-12-04')) AS day_diff, count(*) AS f_count FROM wangchao_data.user_behavior_clean WHERE behavior_type='buy' GROUPBY user_id ), new_biao2 AS ( SELECT user_id, day_diff, f_count, 6-ntile(5) over(ORDERBY day_diff ASC) AS r_score, 6-ntile(5) over(ORDERBY f_count DESC) AS f_score FROM new_biao ORDERBY user_id ) SELECT CASE WHEN (r_score + f_score) >=8THEN'1.核心高价值SVIP(8-10分)' WHEN (r_score + f_score) >=6THEN'2.潜力活跃中产(6-7分)' WHEN (r_score + f_score) >=4THEN'3.濒危沉睡用户(4-5分)' ELSE'4.边缘流失客(2-3分)' ENDAS `用户分层`, count(*) AS total FROM new_biao2 GROUPBY `用户分层` ORDERBY `用户分层` ASC;
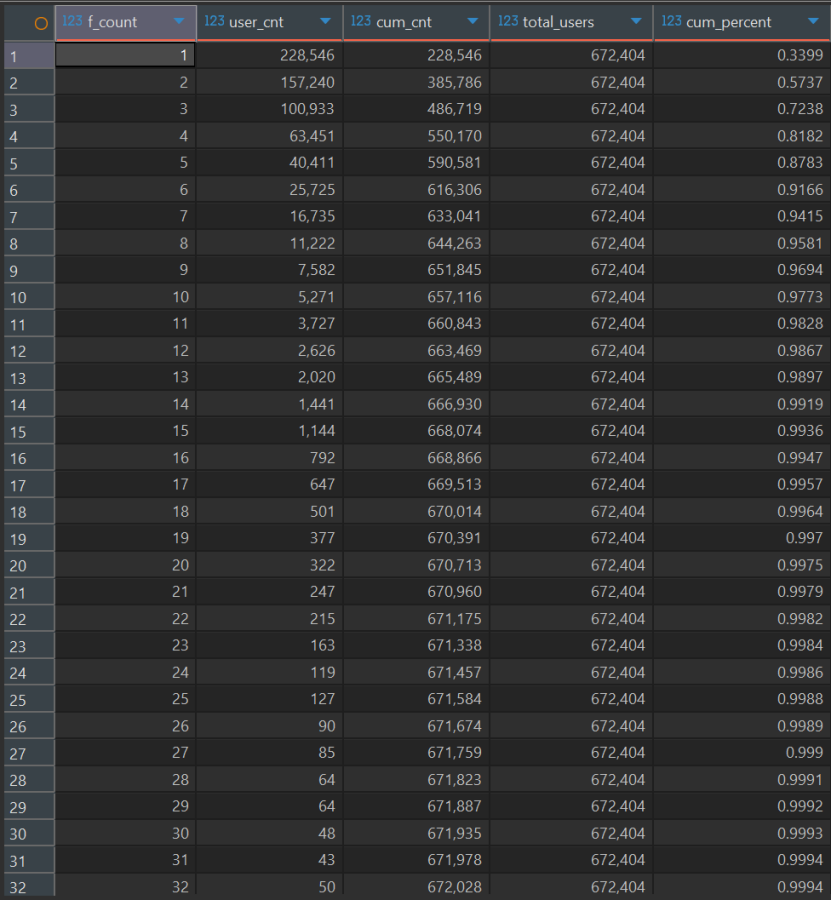
WITH new_biao1 AS ( SELECT user_id, count(*) AS f_count FROM wangchao_data.user_behavior_clean WHERE behavior_type ='buy' GROUPBY user_id ), new_biao2 AS ( SELECT f_count, count(*) AS user_cnt FROM new_biao1 GROUPBY f_count ), new_biao3 AS ( SELECT f_count, user_cnt, sum(user_cnt) over(ORDERBY f_count ASC) AS cum_cnt, sum(user_cnt) over () AS total_users FROM new_biao2 ) SELECT f_count, user_cnt, cum_cnt, total_users, round(cum_cnt/total_users, 4) AS cum_percent FROM new_biao3 ORDERBY f_count ASC;
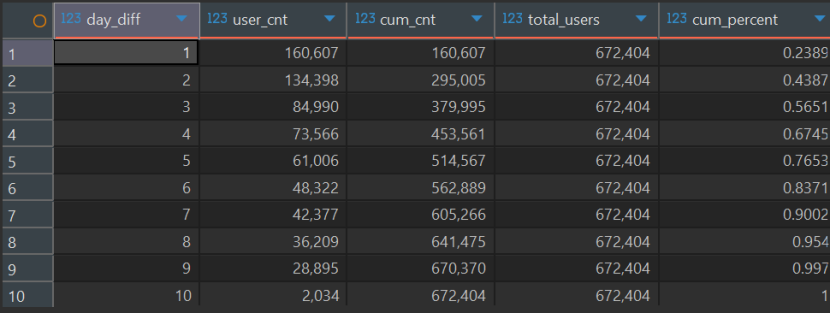
2. R 值(最近购买时间)的自然梯度 即使值域较小,只要分布有自然梯度,也应首选自定义阈值。 本数据集中 R 的值域只有 1-10 天,但实际分布并不极端拥挤(1天占24%,2天占20%,3-4天合计24%,5-7天23%,8-10天10%)。分位点差值明显,存在清晰的时间断点。 此时直接用天数定义层级(如 1天→5分,3-4天→3分)切出来的每层人数相对均衡,且标签是“1天内活跃”这种业务人员能一眼看懂的概念,落地性极强。
WITH new_biao1 AS ( SELECT user_id, dateDiff('day', max(date_id), toDate('2017-12-04')) AS day_diff FROM wangchao_data.user_behavior_clean WHERE behavior_type ='buy' GROUPBY user_id ), new_biao2 AS ( SELECT day_diff, count(*) AS user_cnt FROM new_biao1 GROUPBY day_diff ), new_biao3 AS ( SELECT day_diff, user_cnt, sum(user_cnt) over (ORDERBY day_diff ASC) AS cum_cnt, sum(user_cnt) over () AS total_users FROM new_biao2 ) SELECT day_diff, user_cnt, cum_cnt, total_users, round(cum_cnt/total_users, 4) AS cum_percent FROM new_biao3 ORDERBY day_diff ASC;
三、总结与反思
什么情况下才会转而考虑分桶?——多半是被数据的“极端形态”逼出来的(例如值域跨度极小且高度拥挤,或横跨一整年但极度偏斜)。 在本次项目中,我先对 R 和 F 跑了分位数和累计占比分布,在确认分位点之间的差值足够大、分布并非高度重叠后,才最终决定使用自定义阈值。 这样既让打分有客观的数据锚点,又保留了业务标签的可解释性与稳定性,是目前最适合这套百万级淘宝行为数据的处理方式。不要做代码的搬运工,要让数据真正服务于商业逻辑。